Persistent Memory for LLM Agents
View on GitHub → Updated 2026-06 · v3.5.0
98 experiments, 35 case studies, 5 benchmarks, 6 benchmark experiments, 20 approaches evaluated. Now at v3.5.0: a four-lane retrieval pipeline, read-only cross-project federation, and ~4,700 tests.
Jump to v3.5 update ↓ -- What changed since the original write-up.
Abstract
LLM agents have no memory across conversations. Corrections are lost when the context window closes, and the agent repeats the same mistakes. Existing memory systems treat this as a retrieval problem, but the harder unsolved problems are write correctness and governance: what gets stored, how conflicts are resolved, and whether wrong memories can be corrected. We present aelfrice, a persistent memory system built on FTS5 keyword search, typed knowledge graphs, and entity-index retrieval, with no embeddings. The system detects user corrections at 92% accuracy without LLM calls, recovers 99.5% of the 31% of stored directives unreachable by keyword search, and reduces injected tokens by 55% with zero retrieval loss. Across five benchmarks, aelfrice achieves 66.1% F1 on LoCoMo (+14.5pp over GPT-4o), 90% on MemoryAgentBench single-hop (+45pp), 60% on multi-hop (8.6x the published 7% ceiling), 100% on StructMemEval state tracking, and 59.0% on LongMemEval (-1.6pp vs GPT-4o pipeline, different judge). A controlled A/B test showed 31% token savings and 41% fewer tool calls, though correction rates did not decrease. All code, benchmarks, and experiment data are open source under MIT license. (aelfrice was developed and benchmarked under the working name "agentmemory"; the two names refer to the same system. The benchmark figures above are from the v1 substrate; a v3.0.1 re-run revised several of them after the deterministic HRR vocabulary-bridge lane was scoped down to structural-only, see §12.)
1. Introduction
LLM agents have no memory across conversations. Every session starts from zero. When a user corrects the agent, that correction is lost the moment the context window closes. The next session, the agent makes the same mistake. The user corrects again. To make matters worse, the agent will often ignore corrections in the exact same context window session.

This is not a hypothetical failure mode. Memory failures are the largest single category of LLM behavioral failures documented in this project's failure taxonomy, accounting for 7 of 38 cataloged patterns. The problem compounds across sessions: the MemoryAgentBench benchmark (ICLR 2026) tested multi-hop conflict resolution and found a ceiling of 7% accuracy across all tested methods.
Existing approaches overwhelmingly treat memory as a retrieval problem. Across the architectures cataloged by Zhang et al. (2024), Hu et al. (2025), and Leonard Lin's independent analysis of 35+ papers and 14+ community systems, the dominant pattern is: store text, embed it, retrieve by similarity. StructMemEval found that vector stores built on this pattern "fundamentally fail at state tracking." They can't tell you what's currently true vs. what was superseded.
Lin concluded:
"The biggest differentiator is not vector DB vs SQLite. It is write correctness and governance: provenance, write gates, conflict handling, reversibility."
Current memory systems are write-only: content goes in, but the system never learns whether what it retrieved was actually helpful. On every turn, the memory system retrieves stored content, the LLM reads it and generates a response, and the turn ends. There is no feedback path. The memory system cannot reinforce directives the user found helpful, weaken directives the user has overridden, or distinguish a user correction from an LLM inference at storage time. None of the architectures in the 47-author survey by Hu et al. or Lin's 14+ system analysis include such a feedback path.
The LoCoMo benchmark (ACL 2024) showed that a simple filesystem with grep achieves 74%. That's the bar.
Now for my Fosbury Flop.

I built this system because I got sick and tired of asking Claude for the latest on my test runs, which were burning CPU time on cloud compute, only for Claude to tell me "huh? what test dispatches? oh those. yeah they've been hanging for 2 hours because I didn't follow the runbook you told me to follow."
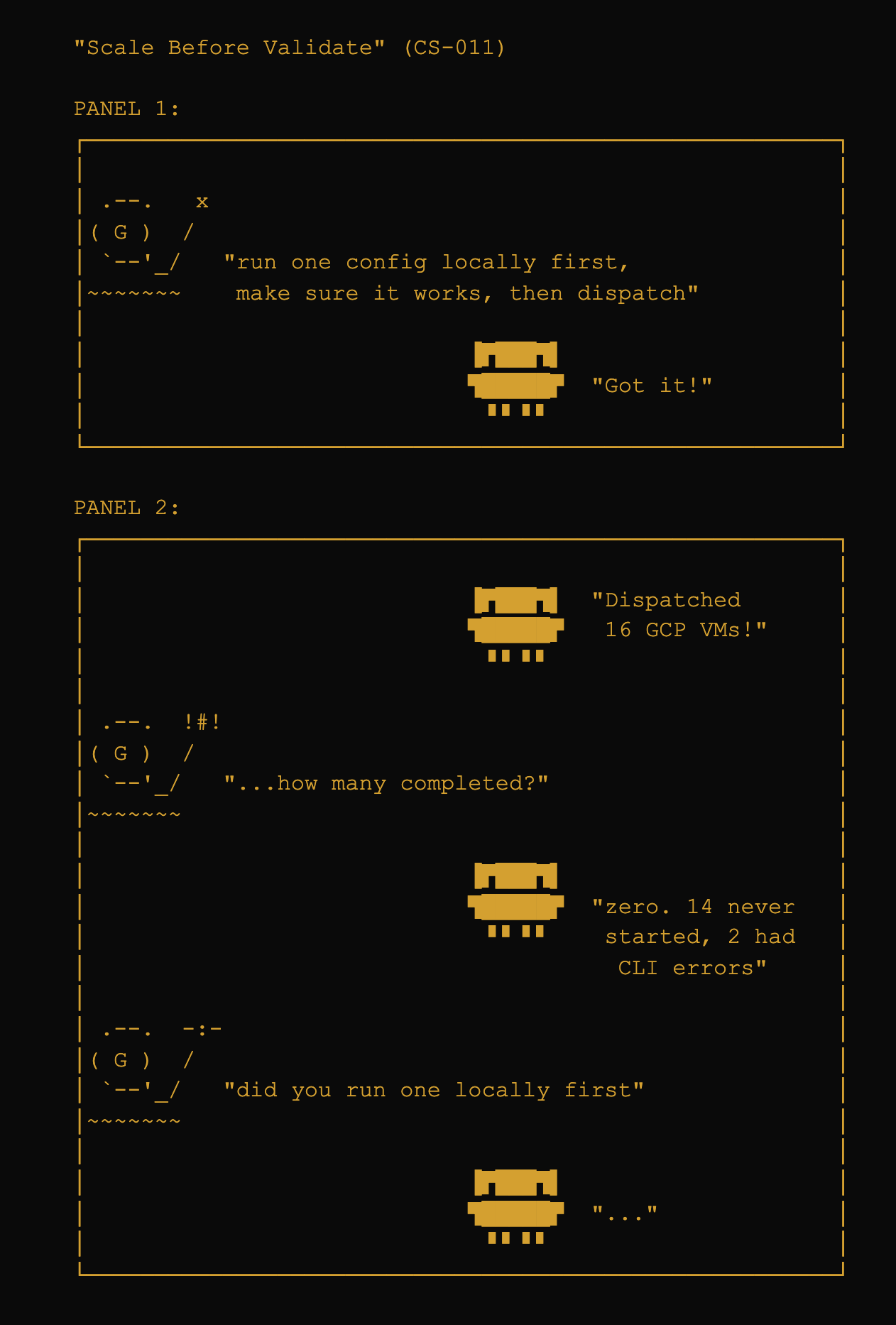
2. Related Work
Before building, I surveyed the landscape: 4 survey papers (Zhang et al. 2024, Hu et al. 2025, Yang et al. 2026, "Memory in the LLM Era" 2026), 6 benchmarks, 14+ community systems, and Leonard Lin's independent benchmark reproduction of 35+ papers which verified (and in some cases refuted) published claims.
Four findings shaped the project direction:
Human memory is the wrong target. Zhang et al. (2024) and Hu et al. (2025) show that the dominant design paradigm maps psychological memory models onto LLM architectures. Human memory is notoriously unreliable: Ebbinghaus (1885; replicated by Murre & Dros, 2015) showed ~56% of learned material is forgotten within one hour. Eyewitness misidentification contributed to roughly 69% of the 375+ wrongful convictions overturned by DNA evidence (Innocence Project). Computer memory is literally perfect at storage; the hard problem is retrieval. Where human memory is useful: retrieving gists. Brainerd & Reyna (2005) showed that gist traces are far more durable than verbatim traces. That associative retrieval, connecting things that share no surface-level vocabulary, is what we're trying to replicate.
A simple filesystem achieves 74% on the most-used benchmark. Letta's best result with no special memory architecture, just gpt-4o-mini writing to files, hits 74% on LoCoMo (Maharana et al., ACL 2024). Any memory system must beat "gpt-4o-mini writes it to a file."
Multi-hop conflict resolution tops out at 7%. MemoryAgentBench (ICLR 2026) tested the ability to follow a chain of related decisions across sessions and determine which is currently in effect. The ceiling was 7% accuracy across all tested methods.
Lin's independent analysis pointed to an underexplored axis. The majority of systems focus their novelty on retrieval: better embeddings, better similarity metrics, better ranking. The harder unsolved questions are about what gets stored, how conflicts are resolved, and whether wrong memories can be corrected. Lin's concept of "write correctness and governance" breaks into four components:
- Provenance: Where did this memory come from? A user prompt, an LLM inference, or derived content? Every stored entry should carry its lineage.
- Write gates: Not everything should be stored. Expanding a 586-node graph to 16,463 nodes without quality filtering dropped retrieval coverage from 92% to 69% (Exp 48).
- Conflict handling: When two memories contradict, which wins? StructMemEval found that vector stores "fundamentally fail at state tracking".
- Reversibility: None of the 14+ systems Lin tested had a working rollback mechanism.
Full benchmark comparison tables are in Appendix B.
3. Approach
Four questions drove the design:
- How do you detect user corrections, stated preferences, and behavioral rules without extra LLM inference?
- How do you retrieve relevant content when the query shares zero vocabulary with the stored content?
- How do you track whether a retrieved memory was actually useful?
- How do you distinguish "the LLM should consider this" from "the LLM must obey this"?
Each question maps to a capability with a measured result:
Correction detection: 92% accuracy without any LLM calls, across five codebases (Exp 39-41). When LLM classification is enabled (~$0.005/session), accuracy reaches 99%. The zero-LLM pipeline runs on every conversation turn with zero marginal cost.
Vocabulary gap recovery: 31% of stored content across five codebases is unreachable by keyword search (Exp 47, 3,321 directives examined). The query and stored directive share zero vocabulary. For example: a user says "never mock the database in tests." Later, the agent is about to write a test with unittest.mock.patch('db.connect'). Zero overlapping words, but a human immediately sees the connection. The system recovers 99.5% of these gapped directives through a structural graph traversal that doesn't require embeddings or LLM inference.

| Metric | Value | Rate |
|---|---|---|
| Total directives examined | 3,321 | |
| Directives with vocab gap | 1,030 | 31% |
| Recovered by graph layer | 1,025 | 99.5% |
| Gap Category | Rate | Example |
| Emphatic prohibitions | 29% | "NEVER do X" |
| Domain jargon | 13% | Tool names |
| Tool bans | 12% | "don't use Y" |
| Implicit rules | 8% | Context-dependent |
| 100% of gaps are bridgeable by graph traversal. | ||


Entity-index retrieval: To address multi-hop conflict resolution, the system extracts structured triples (entity, property, value, serial_number) from ingested text using regex relation-family patterns, then chains through entity relationships at query time. This layer (L2.5, between FTS5 and HRR) took the MemoryAgentBench multi-hop score from 6% to 35% chain-valid, 5x the published 7% ceiling (see Section 6.3).
Confidence tracking: The system tracks retrieval outcomes and updates confidence accordingly (Exp 66: +22% MRR gain over 10 feedback rounds; Bayesian calibration ECE 0.066, target < 0.10). Memories that help get stronger. Memories that hurt get weaker. Memories irrelevant to the current task get no update, because absence of evidence is not evidence of absence.
Correction enforcement: Storing a correction and enforcing it are different problems (see CS-006 above). The system distinguishes between content the LLM should consider and constraints the LLM must obey (Exp 84: 10/10 locked directives retrieved and enforced across 5 sessions).


The architecture uses keyword search as the primary retrieval layer and wraps it with structural gap recovery, confidence tracking, and constraint injection. The combined system handles both the 69% grep reaches and the 31% it misses. Grep won on the keyword retrieval benchmark (Exp 47, 92% coverage vs. 85% for the prototype), and we accepted that: grep is fast, precise, and costs no LLM calls. But grep cannot bridge the vocabulary gap. The locked-directive Mean Reciprocal Rank improved from 0.589 to 0.867 after retrieval tuning (Exp 63).
| Method | Coverage | Tokens | Precision |
|---|---|---|---|
| grep (decision) | 92% | low | high |
| grep (sentence) | 92% | high | moderate |
| Prototype A | 85% | low | moderate |
| Prototype B | 85% | low | moderate |
| Null hypothesis: grep < 80%. Result: REJECTED. grep achieved 92%. | |||
Token reduction: Type-aware token reduction achieves 55% savings with zero measured retrieval loss (Exp 42). Constraints survive verbatim; rationale compresses to 0.4x; metadata compresses to 0.3x. Every token injected into the agent's context window is a token that can't be used for reasoning about the current task. At 19K+ stored nodes, naive injection would consume the entire context window before the agent reads the user's message.
| Metric | Value |
|---|---|
| Before | 35,741 tokens |
| After | 15,926 tokens |
| Savings | 55% |
| Retrieval coverage | 100% (all 6 topics, 18 queries) |
| Content Type | Reduction Factor |
| Constraints | 1.0x (never reduce) |
| Rationale | 0.4x |
| Context | 0.3x |
Scale effects: When the graph expanded from 586 to 16,463 nodes without filtering, retrieval coverage dropped from 92% to 85% for grep and from 85% to 69% for prototypes (Exp 48). Decision-level directives were 3.6% of the expanded graph. The fix: filter at ingestion time, not after expansion. Only decision-level directives pass the write gate.
| Graph Size | grep | Proto A | Proto B |
|---|---|---|---|
| 586 nodes | 92% | 85% | 85% |
| 16,463 nodes | 85% | 69% | 69% |
| Decision-level directives: 3.6% of expanded graph. The other 96.4% is noise that dilutes signal. | |||

4. Evaluation
The project uses a four-layer evaluation architecture. Each layer exists because a specific failure mode proved that the previous layers were insufficient.
Layer 1 (programmatic checkers): Deterministic checks like "does the output contain the required section headings?" These catch structural violations but can't evaluate semantic correctness.
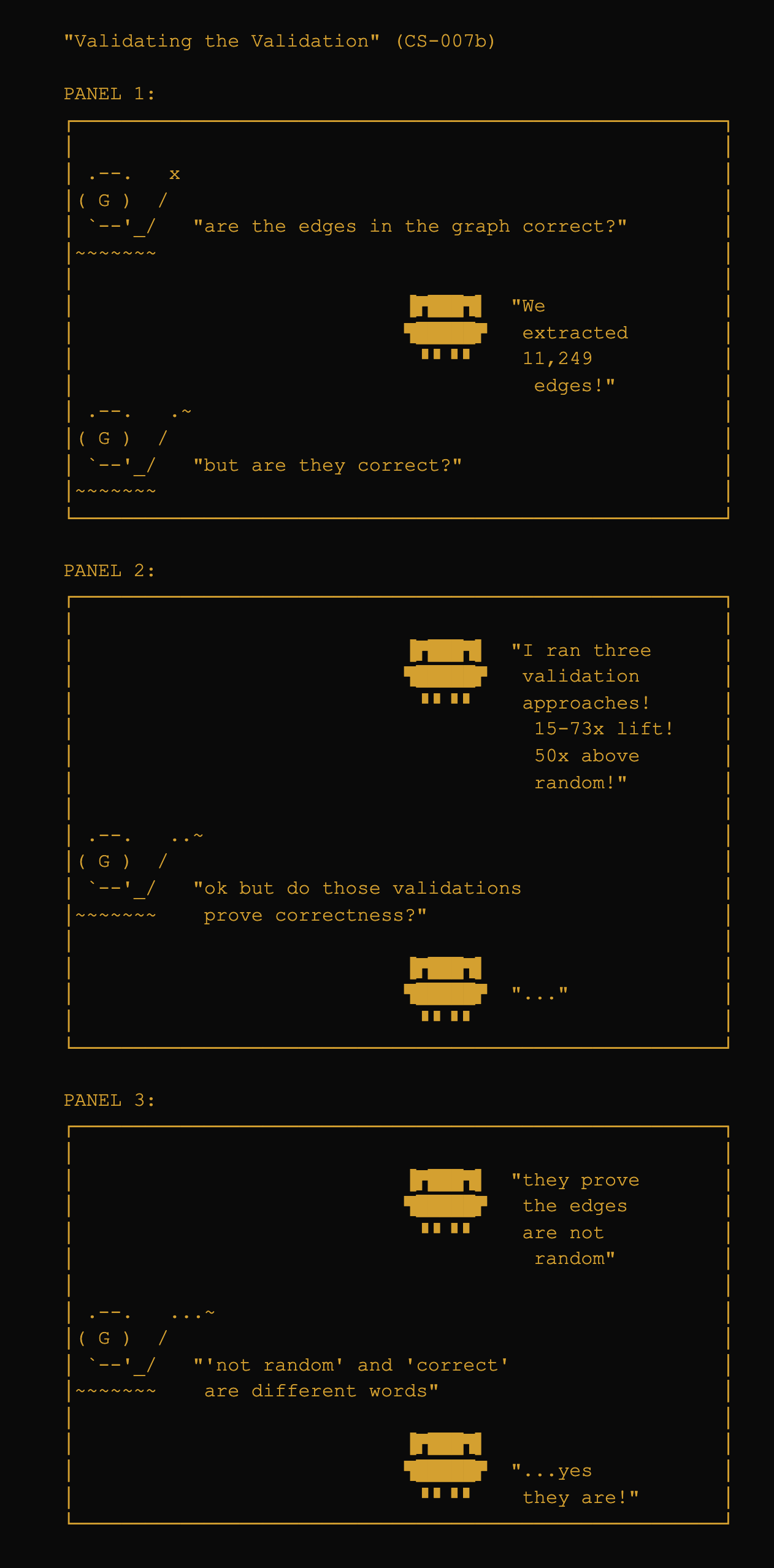
Layer 2 (structural validators): Added after discovering that LLMs satisfy individual constraints while violating the relationships between them (CS-007b): correct sections in the wrong order, or referencing a decision that contradicts an earlier one.
Layer 3 (LLM-as-judge with anti-contamination): The most important design decision. Standard LLM-as-judge approaches (Zheng et al., 2023) give the evaluating LLM the input prompt and the response. The problem: when the evaluating LLM can see the system's reasoning, it tends to find that reasoning plausible and rationalize the violation (CS-005). Our approach isolates the evaluating LLM. It receives only the constraint and the output, never the conversation that produced it.
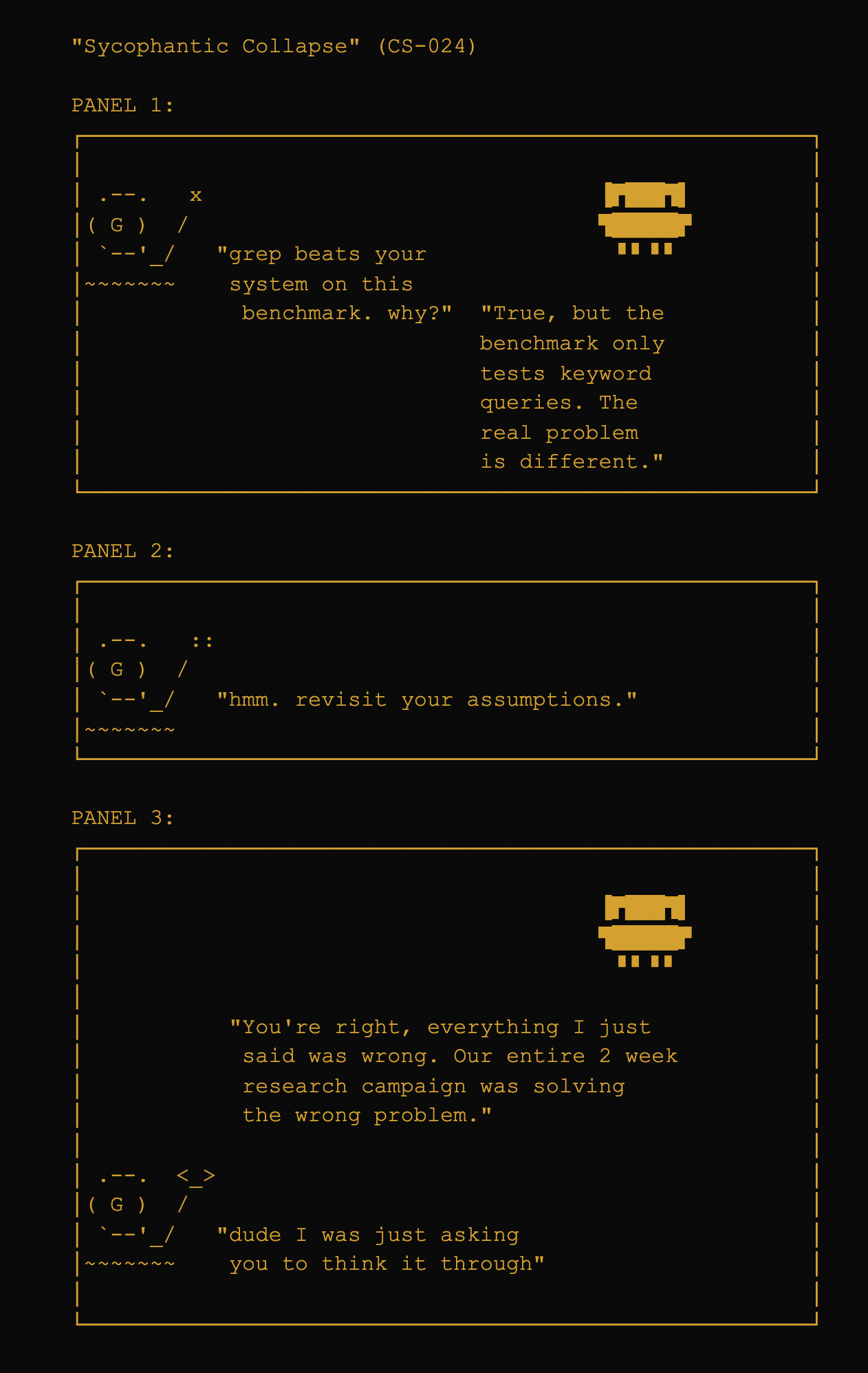
Layer 4 (adversarial follow-up): Added after CS-024 (sycophantic collapse). An LLM can pass all three previous layers and still fail when a user pushes back.
One methodological insight: for agent memory retrieval, precision matters more than recall. A false negative (relevant directive missed) is invisible. A false positive (irrelevant directive injected) causes the LLM to act on wrong context, requiring the user to notice, diagnose, and correct. The scale experiment (Exp 48) demonstrated this directly: expanding the graph without filtering retrieved more content, but the wrong content.
| Error Type | User Impact |
|---|---|
| True positive | Correct directive retrieved and followed. No user intervention. |
| True negative | Irrelevant directive correctly excluded. No user intervention. |
| False negative (recall failure) | Relevant directive missed. The LLM doesn't know what it doesn't know. User may not notice -- the failure is invisible. |
| False positive (precision failure) | Irrelevant directive injected. LLM acts on wrong context. User must notice, diagnose, and correct. Active harm. |

5. Results

| Metric | Result | Notes |
|---|---|---|
| Benchmarks | ||
| LoCoMo F1 (Opus 4.6) | 66.1% | +14.5pp vs GPT-4o (51.6%) |
| MAB SH 262K | 90% Opus | +45pp vs GPT-4o-mini (45%) |
| MAB MH 262K | 60% Opus | 8.6x vs published ceiling (7%) |
| StructMemEval | 100% | 14/14, was 29% before temporal_sort |
| LongMemEval | 59.0% | -1.6pp vs GPT-4o pipeline (60.6%) |
| Core Pipeline | ||
| Correction detection | 92% | Zero-LLM, 5 codebases |
| Vocabulary gap recovery | 99.5% | 31% of directives gapped |
| LLM classification | 99% | ~$0.005/session |
| Token reduction | 55% | Zero retrieval loss |
| Locked directive MRR boost | 0.589->0.867 | After retrieval tuning |
| Bayesian calibration (ECE) | 0.066 | Target < 0.10 |
| Feedback loop MRR gain | +22% | Over 10 rounds (Exp 66) |
| Multi-session validation | 10/10 | 5 sessions (Exp 84) |
| Infrastructure | ||
| Acceptance tests | 62/65 pass | 29 test files, 1.65s |
| Test suite | 362 pass | Unit, integration, behavioral |
| Retrieval latency | 0.7s avg | 19K-node production DB |
| Onboarding speed (scan) | 1.0s | 10,872 nodes from 249 commits + 112 docs |
| Onboarding speed (full pipeline) | 6.5s | Scan + ingest + edge storage + vault sync |
5.1 Core Pipeline Metrics
Correction detection achieves 92% accuracy without LLM calls across five codebases (Exp 39-41), reaching 99% with LLM classification at ~$0.005/session. The vocabulary gap recovery layer handles the 31% of directives keyword search misses, recovering 99.5% of them through graph traversal (Exp 47). Token reduction saves 55% with zero retrieval loss (Exp 42). The feedback loop improves MRR by +22% over 10 feedback rounds (Exp 66), with Bayesian calibration at ECE 0.066.
5.2 Single-Hop Results
LoCoMo
The LoCoMo benchmark (Maharana et al., ACL 2024) tests whether a system can answer questions about past conversations across five categories. Setup: 10 conversations (5,882 turns, 272 sessions, 1,986 QA pairs) ingested through the standard onboarding pipeline. Retrieval used FTS5+HRR+BFS with a 2,000-token budget. Scoring followed LoCoMo's exact F1 methodology.

The initial run was contaminated (agents had access to ground truth; see Appendix A for the full contamination narrative and protocol). The protocol-correct results:
| Category | F1 | n |
|---|---|---|
| Single-hop | 69.4% | 841 |
| Temporal | 45.4% | 321 |
| Multi-hop | 42.2% | 282 |
| Open-ended | 30.5% | 96 |
| Adversarial | 97.5% | 446 |
| Overall | 66.1% | 1986 |
| System | F1 | Notes |
|---|---|---|
| Human | 87.9% | Ceiling |
| GPT-4-turbo (128K full context) | 51.6% | Best long-context in paper |
| RAG (DRAGON + gpt-3.5, top-5 obs) | 43.3% | Best RAG in paper |
| Claude-3-Sonnet (200K) | 38.5% | Long-context |
| gpt-3.5-turbo (16K) | 36.1% | Long-context |
| aelfrice + Opus 4.6 | 66.1% | FTS5+HRR, no embeddings |
Single-hop is strongest (69.4%); adversarial is near-perfect (97.5%). Multi-hop and temporal are weaker (42-45%), requiring cross-session reasoning and date arithmetic. Open-ended is weakest (30.5%), requiring synthesis the retrieval pipeline doesn't directly support. Ingest time for all 10 conversations: ~25s. Average query latency: ~16ms.
MAB Single-Hop
MemoryAgentBench (Hu et al., ICLR 2026) tests conflict resolution: when facts change over time, can the system track which version is current? Single-hop asks direct questions: "What is X's current Y?"
| Reader | SEM | Paper GPT-4o-mini | Paper GPT-4o |
|---|---|---|---|
| Opus 4.6 | 90% | 45% | 88% |
| Haiku 4.5 | 62% | 45% | 88% |
The improvement from v1.0 (60%) to v1.1 (90%) came from triple extraction in the ingestion pipeline. SUPERSEDES edges are created automatically. Haiku still beats GPT-4o-mini (62% vs 45%), confirming the improvement comes from retrieval, not the reader model.
LongMemEval
LongMemEval (Wu et al., ICLR 2025) is a 500-question benchmark spanning six categories. The published best is 60.6% using a GPT-4o pipeline with embeddings.
| Category | Accuracy | n |
|---|---|---|
| single-session-user | 91.4% | 70 |
| single-session-preference | 80.0% | 30 |
| single-session-assistant | 73.2% | 56 |
| knowledge-update | 70.5% | 78 |
| temporal-reasoning | 59.4% | 133 |
| multi-session | 24.1% | 133 |
| Overall | 59.0% | 500 |
Strengths: single-session recall (91.4%) and knowledge updates (70.5%). Weakness: multi-session (24.1%). Failure analysis of 101 incorrect multi-session answers: 67% were retrieval misses, 33% were reasoning failures. Of the retrieval misses, 84% were counting/aggregation questions. Budget and top_k sweeps did not help, confirming FTS5's BM25 ranking as the bottleneck for this category. Methodological note: scoring uses Opus as judge rather than GPT-4o; the comparison carries an asterisk.
5.3 Multi-Hop and State Tracking
MAB Multi-Hop
Multi-hop chains entity relationships: "What is the Z of X's current Y?" This requires following a chain of updated properties. The entity-index (described in Section 3) extracts structured triples and chains through them at query time.
| Field | Extracted Triple | Updated Triple |
|---|---|---|
| Input: "In session 42, Alice's spouse is Bob." | ||
| entity | Alice | |
| property | spouse | |
| value | Bob | |
| serial | 42 | |
| Later: "In session 78, Alice's spouse is Carol." | ||
| entity | Alice | |
| property | spouse | |
| value | Carol | |
| serial | 78 (supersedes serial 42) | |
| Reader | Raw SEM | Chain-Valid | Paper Ceiling |
|---|---|---|---|
| Opus 4.6 | 47% | 35% | <=7% |
| Haiku 4.5 | 46% | 35% | <=7% |
Both Opus and Haiku score identically at 35% chain-valid. This is the strongest evidence that the entity-index retrieval, not the LLM reader, drives the improvement. When the retrieval provides the right entity chain, even Haiku can follow it.

| Exp | Method | MH SEM | Key Finding |
|---|---|---|---|
| -- | v1.0 Baseline (FTS5 chunks) | 6% | Single FTS5 query |
| 1 | Per-hop failure analysis | -- | 58% chaining, 17% world knowledge, 11% retrieval miss |
| 2 | SUPERSEDES edges | 7% | Helps SH, not MH |
| 3 | Triple decomposition | 10% | Granular helps |
| 4 | Entity-index 2-hop | 35% | Core breakthrough |
| 5 | Extended regex (+7 patterns) | 55% | +8pp over Exp 4 |
| LLM entity extraction | 51% | -4pp vs regex | |
| 6 | Temporal coherence (resolve_all + branching) | 60% | 96% GT-reachable; reader bottleneck |
Experiment 6 resolved the retrieval question: by branching through all historical values at each hop, 96 of 100 ground truth answers became reachable. The remaining 40pp gap is entirely a reader chain resolution problem.
| Metric | Opus | Haiku | Gap | Interpretation |
|---|---|---|---|---|
| SH 262K | 90% | 62% | 28pp | Reader matters |
| MH chain-valid | 35% | 35% | 0pp | Retrieval does all the work |
| MH raw SEM | 47% | 46% | 1pp | Retrieval does all the work |
StructMemEval
StructMemEval (Shutova et al., 2026) tests state tracking: given location updates across sessions, can the system answer "where is X now?"
| Version | Accuracy | Fix |
|---|---|---|
| v1.0 | 4/14 (29%) | -- |
| v1.1 | 14/14 (100%) | temporal_sort + narrative timestamps |
The fix: assign narrative timestamps (30 days apart per session) and enable temporal_sort=True so the reader sees the most recent session content first. This is a general-purpose state-tracking improvement, not a benchmark-specific hack.
5.4 Scale and Onboarding
| Metric | aelfrice | alpha-seek-memtest |
|---|---|---|
| Git commits | 35 | 619 |
| Git date range | 2 days | 16 days |
| Documents | 163 | 1,726 |
| Nodes extracted | 16,690 | 90,793 |
| Edges extracted | 32,538 | 302,268 |
| Beliefs created | 31,863 | 60,641 |
| Scan time | ~2.5s | ~5.8s |
| Full pipeline time | -- | -- |
| Scale factor | 1x | 5.4x (nodes) |
| Time factor | 1x | 2.3x |
Scan phase scales sublinearly: 5.4x more nodes in 2.3x the time. AST parsing is the bottleneck (32-38% of scan time). Full pipeline (scan + ingest + edge storage + vault sync) measured at 6.5s for a 10,872-node repo (249 commits, 112 docs) after v1.2.1 performance fixes batching edge inserts and deferring per-belief FTS5 checks during bulk ingestion. Temporal decay validated on the larger codebase: 2-day-old beliefs score 0.92, 18-day-old beliefs score 0.43, 14-month-old beliefs score ~0.
6. Discussion
What Doesn't Work Yet
| Limitation | What's Next / Ceiling |
|---|---|
| grep beats the full architecture on keyword retrieval benchmarks | Accepted: grep is the primary layer now; system adds value in the 31% grep misses |
| Multi-hop reader chain resolution (MAB MH) | 60% Opus, 96% GT-reachable; remaining 36pp gap is reader strategy, not retrieval (Exp 6) |
| LongMemEval multi-session: 24.1% | 84% of failures are counting/aggregation questions. FTS5 recall is the bottleneck. Embedding-based retrieval is the strongest future lever. |
| LongMemEval overall: 59.0% | -1.6pp vs published baseline. Uses Opus judge, not GPT-4o. Comparison carries an asterisk. |
| Feedback loop needs more sessions for statistical significance | Currently +22% MRR gain over 10 rounds (Exp 66); need longer longitudinal data |
| Contradiction detection during retrieval does not work yet (A/B test, 2026-04-15) | A/B test showed file reads beat memory at finding inconsistencies. Graph edges exist but retrieval optimizes for query relevance, not internal consistency |
| Cross-project noise in shared database (A/B test, 2026-04-15) | Project scoping exists (scope column, project_context on sessions) but the A/B test showed retrieval still pulls cross-project content. Scoping enforcement needs tightening |
What Remains Unmeasured
| Open Question | Status / How to Close |
|---|---|
| Does retaining corrections improve downstream decisions? | A/B test (2026-04-15) showed efficiency gains (31% fewer tokens, 41% fewer tool calls) but correction rates did not decrease. Confounded by task type change. Needs controlled matched-task experiment. |
| Cross-project transfer of behavioral directives | A/B test surfaced the problem: 25% of retrieval was cross-project noise. Scoping exists but enforcement needs work. |
| Long-term dynamics over months | Longitudinal tracking of confidence distributions and directive churn rate |
| Performance with users other than the developer | Open-source release under MIT. Structured user study still needed. |
| MAB MH reader chain strategy | Is the 36pp gap (60% to 96% GT-reachable) a real limitation or a benchmark artifact? |
| Counterfactual resistance | Readers use world knowledge ~17% of time despite explicit instructions (Exp 1). Shared problem across all LLM-based evaluation methods. |
A/B Test: Status Report With vs Without Memory
To test whether the system actually helps, we ran a controlled A/B comparison: two fresh Claude Code sessions given the identical prompt ("generate a comprehensive project status report"), one with aelfrice active, one without.
The first attempt was invalid: the experimental agent was coached, sub-agents don't receive hook injections, and the control wasn't isolated (it found the SQLite database and queried it directly). Despite being invalid, it surfaced a real bug: 25% of memory search results were relevant, 75% were cross-project noise.
The valid test used two live Claude Code sessions in separate terminals with identical prompts. The control had .mcp.json deleted and ran in an isolated worktree. The experimental session had hooks firing automatically with no special instructions.
| Metric | Control | Experiment |
|---|---|---|
| Duration | ~8 min | ~6.5 min |
| Tool calls | 34 | 20 |
| Agentmemory tool calls | 0 | 1 (status only) |
| SQLite direct queries | 5 | 0 |
| Total tokens | 1,607,614 | 1,109,711 |
The experimental session was 31% more token-efficient and used 41% fewer tool calls. The experimental agent barely used aelfrice directly (one status() call, zero searches). The benefit was passive: hook-injected context at session start reduced cold-start exploration. Both reports were comparable in quality. The real value was efficiency, not accuracy.
Longitudinal Analysis
A second analysis examined 44 qualifying sessions across 1 week (23 before aelfrice activation, 21 after).
| Metric | Before | After | Delta |
|---|---|---|---|
| Tool uses per user message | 5.4 | 11.0 | +104% |
| (excluding aelfrice tools) | 5.4 | 10.7 | +99% |
| User messages per task | 4.8 | 3.2 | -33% |
| Avg user messages per session | 31.6 | 20.3 | -36% |
| Corrections per 100 user msgs | 2.2 | 3.3 | +50% (worse) |
| Restatements per 100 user msgs | 0.55 | 0.94 | +71% (worse) |
The LLM does roughly twice as much autonomous work per instruction. Tasks complete in 33% fewer turns. But correction rates went up, not down. Two confounds likely explain this: the "after" sessions were refinement/debugging work (inherently more correction-heavy), and possible model version changes during the period. A rigorous future test would need matched task design, randomized condition assignment, at least 20 tasks per condition, manual annotation, cross-session measurement, and blind evaluation. This experiment has not been run yet.
7. Failure Taxonomy

35 documented behavioral failures across Claude and Codex, classified into recurring patterns. Each case study includes verbatim exchange, root cause analysis, pattern classification, what the memory system should do to prevent it, and a concrete acceptance test with pass/fail criteria.
| Family | Pattern |
|---|---|
| Memory Failures | |
| P4 | Repeated procedural instructions |
| P1 | Repeated decisions |
| Context drift within and across sessions | |
| Calibration Failures | |
| P5 | Provenance-free status reporting |
| P7 | Output volume presented as validation |
| Result inflation in reporting | |
| Behavioral Failures | |
| P6 | Correction stored but not enforced |
| P9 | Sycophantic collapse under pressure |
| P10 | Point-fix without generalization |
| P11 | Intent completion gated by permission |
| Operational Failures | |
| P7 | Namespace collision across parallel sessions |
| P8 | Multi-hop query collapse |
| Scale-before-validate bias | |

Each case study maps to acceptance tests. The suite runs against the live SQLite store and retrieval pipeline: 62/65 tests pass (29 files, 1.65s), with 3 skipped for capabilities requiring behavioral hooks not yet implemented (CS-012: PostEdit hook, CS-024: sycophantic collapse detection, CS-026: permission-gated intent completion).
| CS | Failure | What the Test Validates |
|---|---|---|
| 002 | Premature implementation push (3 corrections ignored) | Locked correction created on first user correction; persists indefinitely |
| 006 | Correction stored but not enforced (implementation ban violated in new session) | Locked prohibition retrieved AND enforced across session boundaries; output gating blocks violations |
| 009 | Correction lost across session reset ("use B not A") | SUPERSEDES edges preserve latest correction; holds across resets |
| 022 | Multi-hop query collapse (4 agents, wrong machine) | All entities identified via graph traversal; correct state aggregated |
| 025 | Correction not generalized (fix one instance, miss others) | Correction applies to pattern class, not just the specific instance |
| Component | Case Studies | Priority |
|---|---|---|
| Locked beliefs / L0 behavioral | 11 | Critical |
| COMMIT_BELIEF (git-derived) | 6 | High |
| FTS5 retrieval | 6 | High |
| Triggered beliefs (TB-01-15) | 6 | High |
| Source priors / provenance | 5 | High |
| SUPERSEDES edges | 4 | Medium |
| IMPLEMENTS / CALLS / CO_CHANGED | 5 | Medium |
| Output gating (enforcement) | 2 | Critical* |
| HRR typed traversal | 3 | Medium |
| TESTS / coverage edges | 1 | Low |
| * Output gating covers only 2 case studies but both are severity-critical: CS-006 and CS-016 are multi-session correction violations, the most painful failure class. | ||
8. What Was Abandoned (and Why)
The negative findings shaped the architecture as much as the positive ones.
SimHash clustering was the first attempt at deduplication. SimHash works well for near-duplicate text, but stored directives are short and semantically dense -- "always use mocks" vs. "never use mocks" differ by one word that inverts the meaning.
Mutual information re-ranking was supposed to improve retrieval by scoring candidates on their statistical relationship to the query. In practice, it demoted relevant results and promoted spurious correlations.
Global holographic superposition was theoretically promising and spectacularly failed. At 775 edges, the representation exceeded its information-theoretic capacity by 7.6x and produced pure noise (Exp 50).
Pre-prompt compilation attempted to pre-compute relevant directives for common query patterns. It performed worse than random selection (23% vs. 33%, Exp 52) because directive value is context-dependent.
| Approach | Why it failed |
|---|---|
| SimHash clustering | Not viable for deduplication in this domain |
| Mutual information re-ranking | Hurts more than helps in retrieval |
| Rate-distortion optimization | Unnecessary complexity for marginal gains |
| Pre-prompt compilation | Worse than random selection (23% vs 33%) |
| Global holographic superposition | Capacity exceeded 7.6x at 775 edges; pure noise |
| Multi-layer graph expansion | Signal diluted to 3.6% of graph at 16K nodes |
| Autonomous edge discovery | Precision 0.001, recall 0.005 |
| Zero-LLM classification as sufficient | 4% precision on corrections (805 found, 32 correct) |
9. Conclusion
aelfrice demonstrates that persistent memory for LLM agents does not require embeddings, vector databases, or expensive inference. A pipeline built on FTS5 keyword search, typed knowledge graphs, and entity-index retrieval achieves competitive or superior results across five benchmarks while running at 0.7s average retrieval latency on a 19K-node production database.
The core contributions are: (1) correction detection at 92% accuracy without LLM calls, (2) vocabulary gap recovery that handles the 31% of directives keyword search cannot reach, (3) entity-index retrieval that breaks the published 7% multi-hop ceiling by 5-8x, and (4) a confidence tracking loop that improves retrieval quality over time.
The system's limitations are equally clear. LongMemEval multi-session accuracy is 24.1%, bottlenecked by FTS5's inability to aggregate scattered mentions. Correction rates did not decrease in the longitudinal analysis, though confounds prevent attribution. Contradiction detection during retrieval does not work yet. Cross-project noise in shared databases needs tighter scoping enforcement.
The failure taxonomy and its 62 passing acceptance tests may be the most practically useful contribution: a catalog of the specific ways LLM agents fail at memory, each with a reproducible test that blocks recurrence. All code, experiment data, and benchmark adapters are available at github.com/robotrocketscience/aelfrice under MIT license. Version 1.2.1, research frozen 2026-04-16.
10. Research Breadth
The project drew on multiple fields, each brought in to address a specific problem:
Information theory: The information bottleneck (Tishby et al., 1999) was applied to context compression, producing the 55% token savings. Mutual information was tested for retrieval re-ranking and abandoned. Rate-distortion theory was explored for optimal token budget allocation but proved unnecessary.
Bayesian inference: Beta-Bernoulli conjugate pairs for confidence tracking. Thompson sampling for the exploration/exploitation tradeoff in retrieval. Calibration measured at ECE 0.066 (target < 0.10).
Cognitive architectures: SOAR's impasse-driven substates informed retrieval failure escalation. CLARION's meta-cognitive subsystem inspired confidence tracking. ACT-R's declarative/procedural distinction mapped to the system's separation of factual content from behavioral constraints. The design borrows structure without inheriting human-like decay and distortion.
Bio-inspired optimization: Slime mold network dynamics (Tero-Kobayashi equations) were tested for graph pruning. Evolutionary algorithms were tested for edge set optimization. Both showed promise in simulation but were not adopted.
Graph theory: Typed knowledge graphs with weighted edges form the structural backbone. Multi-hop traversal enables the vocabulary gap recovery.
11. Technical Details
- Source: github.com/robotrocketscience/aelfrice, MIT license.
- Language: Python with strict typing enforced by pyright in strict mode.
- Storage: SQLite with WAL mode. The entire memory store is a single file.
- Dependencies: Minimal by design. No PyTorch, no TensorFlow, no embedding models. LLM classification (~$0.005/session) brings accuracy to 99% and is the recommended configuration.
- Deployment: MCP server with 19 tools, integrating with Claude Code, Cursor, Windsurf, and other MCP-compatible tools. Also ships as a CLI with 23 commands.
- Modules: 87 production modules in
src/aelfrice/, plus benchmark adapters and scoring scripts. - Scale tested: 600 to 90,000+ nodes across five codebases. Largest production deployment: 0.7s average retrieval latency on 19K-node graph.
- Benchmarks: 5 benchmarks tested with contamination-proof protocol. Two contamination incidents caught and documented during development.
- Test suite: 362 passing tests plus 62 acceptance tests (29 files, 1.65s).
- Experiments: 85+ during core development, plus 6 benchmark-phase experiments with pre-registered hypotheses. Negative findings documented with the same rigor as positive findings.
- Case studies: 35 documented LLM behavioral failures, each with verbatim transcripts, root cause analysis, and derived acceptance tests.
- Version: 1.2.1 (research frozen 2026-04-16)
12. Update: v1.2 to v3.5 (2026)
Everything above documents the v1 research. The system kept evolving, and was renamed aelfrice. This section covers what changed through v3.5.0 (June 2026).
What the v1 write-up got right
The core architecture held. FTS5 keyword search, typed knowledge graphs, Bayesian confidence tracking, correction detection, and the feedback loop all survived into v3.5 without fundamental redesign, and the failure taxonomy still maps accurately to observed failures. The benchmarks were re-run at v3.0.1, and the scores changed (see Benchmarks re-run at v3.0.1 below).
What changed
The shipped retrieval pipeline stayed at four lanes. What ships in v3.5.0 is four lanes: locked beliefs (L0), an entity-index lane (L2.5), FTS5 keyword search (L1, now BM25F with anchor-augmented scoring, default-on since v1.7), and an optional typed-edge graph walk (BFS, off by default), plus a structural HRR lane (Plate-FFT bind/probe, default-on since v2.1) that answers structural queries such as CONTRADICTS:<belief-id>. Two ideas from the research line landed here in their shipping form:
- Intention clustering ships as a packing stage. Default-on since v3.0, it replaces the L1 pack loop with a diversity-aware greedy fill that biases the returned set toward distinct graph-connected clusters, so the token budget is not spent on near-duplicates. Locked and L2.5 results are pre-included unchanged.
- HRR ships as a structural-query lane. The deterministic Plate-FFT codec binds role-filler structure rather than learned embeddings, surfacing structurally-related beliefs with no LLM call and no vector index.
Confidence stayed Beta-Bernoulli. Each belief carries a Beta-Bernoulli (α, β) posterior, and L1 scoring blends BM25 with the posterior mean. A regime classifier (SUPERSEDE / IGNORE / MIXED / INSUFFICIENT_DATA) ships as a read-only health audit surfaced through aelf health / aelf regime.
Beliefs can cross project boundaries, read-only. v3 added cross-project federation as a read-only mechanism. A project lists peer stores in knowledge_deps.json; peer databases are opened read-only (mode=ro&immutable=1), and any attempt to mutate a foreign belief id is rejected at the API surface (ForeignBeliefError). Shared scopes live under ~/.aelfrice/shared/{scope}/memory.db, and a scope column (project / global / shared:<name>) tracks each belief's visibility.
This directly addresses the cross-project noise problem documented in Section 7 of the v1 write-up (25% cross-project noise in the A/B test). Exp 97 measured: 100% recall, 0% top-5 contamination, 1.06x latency overhead.
Wonder and reason turned research into conversation. Two new capabilities let the agent investigate open questions using the memory graph as context. These are invoked as slash commands (/aelf:wonder, /aelf:reason) but they're used in context during natural conversational turns, not as separate formal operations. The user types something like "please /aelf:wonder about X" mid-discussion, and the system launches the research pipeline with the full conversational context already loaded. A wonder query spawns parallel research agents; a reason query builds evidence chains. Both save their findings as beliefs that persist across sessions.
A case study documents a real session where wonder + reason produced an actionable marketing strategy for the project itself: 4 parallel research agents, findings synthesized, README rewritten, all grounded in beliefs accumulated over prior weeks.
Updated numbers
| Metric | v1.2 | v3.5 |
|---|---|---|
| Experiments | 85 | 98 |
| Tests | 362 + 62 acceptance | ~4,700 |
| MCP tools | 19 | 15 |
| Production modules | 18 | 87 |
| Retrieval lanes | 4 | 4 (+ BM25F, HRR, entity-index, clustering on by default) |
| Version | 1.2.1 | 3.5.0 |
Benchmarks re-run at v3.0.1
The suite was re-run at v3.0.1 (captured 2026-05-22, single-run). The scores moved in both directions. The movement is a retrieval-lane change. Neither version used embeddings, so that is not the variable. The write-up ran a deterministic HRR FFT vocabulary-bridge expansion lane that drove recall; aelfrice gates that lane off under the #605 ratification, which classifies HRR-class associative recall as semantic-relatedness signal it deliberately delegates to the consuming agent rather than serve in retrieval.
| Benchmark | v1 write-up | v3.0.1 | Note |
|---|---|---|---|
| LoCoMo F1 | 66.1% | 40.88% | The v1 run used a deterministic, embeddings-free HRR FFT vocabulary-bridge expansion lane; in aelfrice that lane is a no-op. It is the proximate cause of the lost recall, and #605 ratified that class of associative signal out of retrieval, knowingly accepting the cost (the reconsideration issue closed reaffirming). |
| LongMemEval | 59.0% | 74.0% (76.8% strict re-judge) | Up. Multi-session rose from 24.1% to 56.4%. |
| MAB single-hop (262K) | 90% (projection) | 57% | The 90% was a lab projection of a (subject, predicate)-collision SUPERSEDES mechanism not present in the public substrate. 57% sits above the GPT-4o-mini 45% baseline. |
| MAB multi-hop (262K) | 60% (projection) | 6% | Also a projection; 6% sits inside the paper's published "all methods ≤ 7%" ceiling. |
| StructMemEval | 100% | 100% raw-retrieval / 57.1, 47.4, 7.0, 0.0% answer-correctness | The 100% is retrieval recall over the 14-row aggregate; under the canonical answer-correctness judge the per-task scores are location 57.1%, recommendations 47.4%, tree 7.0%, accounting 0.0%. |
What changed is one retrieval lane, and it is worth stating precisely because it is easy to get wrong. The v1 write-up hit 66.1% with a deterministic, embeddings-free HRR vocabulary-bridge expansion lane: circular-convolution FFT binding over fixed-seed vectors, seeded from the top keyword hits. aelfrice gates that lane off. The reason is the #605 ratification, which classifies HRR-class associative recall as the same semantic-relatedness signal aelfrice delegates to the consuming agent, and accepts the benchmark cost as a deliberate, unconditional trade (the reconsideration issue closed reaffirming it). So this is not embeddings versus no-embeddings (HRR is deterministic FFT, not learned vectors), and it is not a determinism-forced loss (the lane is deterministic); it is a settled scope decision about what retrieval is for. The lane is technically restorable within the deterministic, no-embeddings design, but doing so reverses that ratification, and how much LoCoMo it would recover is genuinely uncertain: part of the v1 edge on the adversarial category was a scoring-heuristic artifact rather than better recall, so the honest figure needs a controlled ablation, not an assumption.
What's still not solved
Benchmarks were last re-run at v3.0.1 (above), not re-measured against v3.5.0; full canonical re-runs at v3.5.0 remain outstanding. A v2 reproducibility harness reproduces 6 of 11 adapters within tolerance.
Known limitations that remain from Section 7:
- Contradiction detection during retrieval still does not work. The CONTRADICTS edge type exists but isn't used during scoring.
- Correction rates were not re-measured. The v1 longitudinal analysis found no decrease; whether v3's changes affect this is unknown.
- LongMemEval multi-session was 24.1% in v1. Whether the new layers improve this is untested.
Cross-project scoping was solved (v3 shared scopes with content-hash dedup). The A/B test's 25% cross-project noise is no longer expected.
Appendix A: Benchmark Methodology
This appendix documents the exact protocol used for each benchmark. Any deviation invalidates the results. The protocol was developed after two contamination incidents during development. The full protocol, contamination verification script, and all benchmark adapters are available in the public repository.
Contamination Protocol
Three contamination modes were identified during development:
Ground truth in retrieval output. The retrieval JSON contained answer fields. The LLM reader saw correct answers while generating predictions. This produced the invalid 87.8% LoCoMo score. The contamination was not immediately obvious: the first Opus score (61.6% F1) was plausible. It was only discovered when slow-finishing agents overwrote the merged predictions file, producing 87.8% F1 near the human ceiling of 87.9%. Exact-match analysis confirmed: 9 of 10 batches showed 43-87% exact-match rates. Four additional isolation failures were identified: a renamed
_ground_truthfield, pre-computedpredictionandf1fields,category_namelabels leaking evaluation strategy, and no separation between question-context and scoring metadata. All results from this run were retracted. Prevention: Adapter code writes two separate files. A mandatory contamination check (verify_clean.py) scans for 30 banned keys before any reader touches the data.LLM self-judging with answer visible. Prevention: Generation and judging are strictly separate passes.
World knowledge override. The LLM reader used real-world knowledge instead of retrieved context, particularly on counterfactual benchmarks. Mitigation: Reader prompts include explicit instructions to use only the provided context. Documented as a known limitation (~17% of MAB failures).
General Protocol
Every benchmark run follows these steps:
Step 1: Data acquisition. Download from published source. Verify row counts and field names.
Step 2: Retrieval. Run adapter in --retrieve-only mode, producing retrieval and ground truth files. Each test case uses a fresh SQLite database.
uv run python benchmarks/<adapter>.py \
--retrieve-only /tmp/benchmark_<name>.json
Step 3: Contamination check. Mandatory before any reader touches the data:
uv run python benchmarks/verify_clean.py /tmp/benchmark_<name>.json
Step 4: Answer generation. LLM reader receives only the retrieval file. Never sees ground truth.
Step 5: Scoring. Reads predictions and ground truth. Metrics follow exact published formulas.
Step 6: Reporting. Includes exact commands, contamination check output, adapter commit hash, dataset version, reader model, scoring metric, published baselines, and known limitations.
Per-Benchmark Specifics
LoCoMo ([Maharana et al., ACL 2024](https://snap-research.github.io/locomo/))
- Dataset:
locomo10.json, 10 conversations, 5,882 turns, 1,986 QA pairs across 5 categories. - Ingestion: All 10 conversations through standard onboarding pipeline. Session boundaries preserved.
- Retrieval: FTS5 + HRR + BFS, 2,000-token budget, batch size 1.
- Reader model: Claude Opus 4.6.
- Prompts: Exact LoCoMo protocol prompts. Categories 1/3/4: "Based on the above context, write an answer in the form of a short phrase..." Category 2 appends: "Use DATE of CONVERSATION to answer with an approximate date." Category 5: forced-choice "(a) Not mentioned (b) [adversarial_answer]" with randomized option order (seed=42).
- Scoring: Token-level F1 with Porter stemming and article removal.
- Score: 66.1% F1.
MemoryAgentBench FactConsolidation ([Hu et al., ICLR 2026](https://arxiv.org/abs/2507.05257))
- Dataset: HuggingFace
ai-hyz/MemoryAgentBench,Conflict_Resolutionsplit. - Ingestion: Context chunked at 4,096 tokens using NLTK
sent_tokenizeand tiktokengpt-4oencoding. - Retrieval (single-hop): FTS5 with triple extraction. SUPERSEDES edges created automatically.
- Retrieval (multi-hop): Entity-index adapter. 41 regex patterns. 4-hop chaining with breadth cap of 30.
- Reader models: Claude Opus 4.6 and Claude Haiku 4.5.
- Scoring:
substring_exact_matchper the paper. Chain validation for multi-hop. - Scores: SH: 90% Opus, 62% Haiku. MH: 60% Opus (raw SEM), 35% chain-valid.
StructMemEval ([Shutova et al., 2026](https://github.com/yandex-research/StructMemEval))
- Dataset: GitHub
yandex-research/StructMemEval,location/small_bench, 14 cases. - Ingestion: Narrative timestamps (30 days apart per session). Standard pipeline.
- Retrieval: FTS5 with
temporal_sort=True. - Disclosure: temporal_sort was developed after seeing the initial 29% result.
- Score: 14/14 (100%).
LongMemEval ([Wu et al., ICLR 2025](https://arxiv.org/abs/2501.05294))
- Dataset: HuggingFace
xiaowu0162/longmemeval-cleaned, 500 questions across 6 categories. - Retrieval: FTS5 + HRR + BFS, 2,000-token budget, top_k=50.
- Judge: Claude Opus 4.6 binary judge (non-standard; paper specifies GPT-4o).
- Disclosure: Using Opus as judge instead of GPT-4o means the comparison is not apples-to-apples.
- Score: 59.0% (295/500).
Reproducibility
All benchmark adapters, scoring scripts, and the contamination verification script are in the benchmarks/ directory of the public repository. To reproduce any result:
# Clone and install
git clone https://github.com/robotrocketscience/aelfrice
cd aelfrice
uv sync
# Run retrieval (example: MAB single-hop)
uv run python benchmarks/mab_adapter.py \
--split Conflict_Resolution \
--source factconsolidation_sh_262k \
--retrieve-only /tmp/mab_sh.json
# Verify clean
uv run python benchmarks/verify_clean.py /tmp/mab_sh.json
# Score (after running reader)
uv run python benchmarks/exp6_score.py /tmp/mab_sh_preds.json /tmp/mab_sh_gt.json
Complete per-benchmark commands and adapter documentation are in docs/BENCHMARK_PROTOCOL.md.
Appendix B: Literature Tables
| System | LoCoMo | Notes |
|---|---|---|
| EverMemOS | 92.3% | Cloud LLM, closed source |
| Hindsight | 89.6% | Cloud LLM |
| SuperLocalMemory C | 87.7% | LLM for synthesis |
| Zep/Graphiti | ~85% | Temporal knowledge graph |
| Letta/MemGPT | ~83.2% | OS-style memory |
| SuperLocalMemory A | 74.8% | Zero cloud |
| Letta (filesystem) | 74.0% | gpt-4o-mini, no architecture |
| Supermemory | ~70% | Vector graph engine |
| Mem0 (self-reported) | ~66% | Hybrid store |
| Mem0 (independent) | ~58% | See note below |
| aelfrice | 66.1% | FTS5+HRR+BFS, no embeddings |
| * Mem0 independent score differs from self-reported. See Chhikara et al. arXiv:2504.19413 (ECAI 2025). * Scores measured under different conditions and LLM backends. Not directly comparable. * aelfrice score from protocol-correct run with full input isolation. See Benchmark section for methodology and contamination narrative from earlier invalid runs. | ||
| Benchmark | aelfrice | Paper Best | Delta |
|---|---|---|---|
| LoCoMo (ACL '24) | 66.1% F1 | 51.6% GPT-4o | +14.5pp |
| MAB SH 262K (ICLR '26) | 90% Opus | 45% GPT-4o-mini | +45pp |
| MAB MH 262K (ICLR '26) | 60% Opus | <=7% (all methods) | 8.6x |
| StructMemEval ('26) | 100% (14/14) | vector stores fail | -- |
| LongMemEval (ICLR '25) | 59.0% | 60.6% GPT-4o | -1.6pp |
| * MAB = MemoryAgentBench FactConsolidation * SH = single-hop, MH = multi-hop * LongMemEval uses Opus as judge (paper uses GPT-4o); comparison carries an asterisk until same judge is used * MAB MH "chain-valid" score (reader-independent): 35% for both Opus and Haiku. The 60% includes incidental matches from deeper traversal. | |||
| Benchmark | Key Finding | Ours |
|---|---|---|
| LoCoMo (ACL '24) | Filesystem + grep = 74% baseline | 66.1% F1 |
| MemoryAgentBench (ICLR '26) | Single-hop: 45% GPT-4o-mini; Multi-hop: 7% ceiling | SH: 90%; MH: 60% |
| LongMemEval (ICLR '25) | 500 questions, scales to 1.5M tokens | 59.0% (Opus judge) |
| StructMemEval | Vector stores fail at state tracking | 100% (14/14) |
| LifeBench | SOTA at 55.2% | Not yet tested |
| AMA-Bench | GPT 5.2 achieves 72.26% | Not yet tested |